I spoke previously about the dangers of survivorship bias and the relevance of start date. I also spoke about the need to keep data out of sample and to keep the number of optimisable parameters as low as possible in order to avoid data mining.
As well, I mentioned how the only true out of sample data is future data since we already have an awareness of what the market has done in the past.
In this article I will be talking about another important topic known as selection bias. In trading system development, selection bias can occur when a trader backtests so many trading ideas that he will almost certainly come across a good looking backtest, only to find that it is no more than a random fluke.
This is a concept that has been well explained by Michael Harris at the PAL blog.
Selection Bias in Trading Systems
Consider the process of testing and optimising a trading system. Using a computer and a trading platform it is possible to test hundreds and thousands of different combinations of settings.
If you test enough different strategies you will eventually find one that presents strong returns and exhibits a very attractive looking equity curve.
Most traders will realise at this point, that if you are planning on risking your hard earned money in the market, you cannot rely simply on one good looking equity curve.
A single equity curve does not provide enough confidence to trade and may only have come about by pure chance. The issue is that the profit potential of the system may be random and therefore unlikely to be repeated in the future.
Some inexperienced traders may believe that they have just stumbled across the ultimate winning trading system. But in reality, if the system is random it will start underperforming as soon as it is taken live.
Eye Balling Equity Curves
Michael Harris talks about an interesting coin toss analogy that we can use to help explain this issue.
Let’s say that you are in the business of building trading systems and you’re looking for a system with low drawdowns, positive expectancy and a smooth, upward sloping equity curve.
If so, what do you think of the equity curve below?
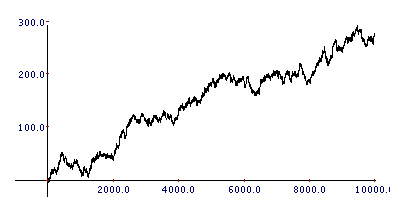
I’m sure you’ll agree that this is a decent looking equity curve. It certainly doesn’t look like a random chart. If your trading account could grow at a consistent rate like this chart for a number of years then I’m sure you’d be quite happy.
But what if I told you that the curve above was actually the result of 10,000 random coin tosses?
That’s right, random outcomes can generate beautiful looking equity curves. Even with a sample size as large as 10,000.
So even though the outcome of a coin toss is 50/50 between heads and tails, run several simulations and you can come across some quite outrageous win/loss sequences and therefore some outrageous looking charts. Charts that look anything but random.
So, the problem is that an attractive equity curve can fool a trader into believing they have a profitable trading system that is not random.
This problem can get worse when the trader gets a positive equity curve in the out-of-sample too, which may also have come about by pure chance.
This can happen for exactly the same reason. If you test enough strategies, you will eventually find one that looks good in both in-sample and out-of-sample, yet the whole result may still be a fluke, unlikely to be repeated in the future when you take the system live.
This problem is even more likely to occur when the trader uses only a small amount of in-sample or out-of-sample data. Since the smaller the size of the sample, the easier it is for random outcomes to occur. Refer to the law of small numbers.
Is Your Trading System Random?
Knowing this information is important but how can traders build trading systems and be confident that they are not random flukes?
Well the answer is not always simple and has a lot to do with statistics. But for starters we can make sure to employ some basic principles:
1) Make sure to base your trading system on theoretical principles before you begin to build it. Don’t search for profitable patterns within the data as you will be sure to find plenty of profitable patterns that are in fact random. This is an easy path to find random flukes and become seduced by the results on screen.
If you do decide to go this route, then make sure you have exhaustive processes in place to measure the robustness of your patterns.
2) Always keep enough out-of-sample data for validation of the system. Once you have tested the system in-sample, test it just once on the out-of-sample data to see if it performs in a similar way.
Don’t go back to the in-sample data and adjust your system based on the out-of-sample results because by doing so you contaminate the data and make curve fitting much easier. In essence, you are cheating by using the recent data to inform the rules during the in-sample phase.
The more times you test your data the more likely you will find a fluke and the harder it will be for you to tell.
Further, you can choose to include out-of-sample data before your in-sample data as well as after your in-sample data. It can go at the end or at the beginning. Or both.
You can also run your strategy using different start dates and different data ‘windows’ to get a better idea of whether your initial run was a fluke. Walk-forward analysis can also be set up to automate this process in a logical way.
3) Keep the number of parameters as small as possible. Increasing the number of adjustable parameters increases the number of equity curves that can be generated and increases the likelihood of data mining in an exponential fashion.
There are profitable trading systems out there that consist of just one or two adjustable parameters. Such strategies are more easily tested for significance and therefore are more likely to be robust.
4) When optimising parameters, don’t necessarily choose the best performing variable. Look for a range of variables where the system performs well and then pick something that sits within that range.
For example, if a system performs well on a 100 day breakout, it should also perform well on a 98 or 95 day breakout. Or a 102 or 110 day breakout.
If you have a system that makes 20% per annum using a 100 day breakout but loses money with a 99 day or 101 day breakout, then it’s likely you got a fluke result with your 100 day system. Small changes in parameters should not have a big effect on final results.
If your system doesn’t perform well with very similar variables then there’s a good chance the result is random.
5) Test your system on other markets. Just as you would test your system on out-of-sample data to measure it’s robustness, you can also test your system on other markets.
A system that works well on crude oil may not necessarily need to work on gold, but if it does, it adds an extra layer of confidence that you may have found an edge.
6) Use significance tests like Monte Carlo and White’s Reality Check to confirm your system results against a base, random result. You want to be able to disprove the hypothesis that says your system might be random.
In other words, you want to be able to say that your system results are so good that it is highly unlikely to be a random result.
For example, you might look for a significance level that will allow you to say that you are 99% confident your system is not random. In science, you can never be totally sure of anything. The best you can do is to prove that something is not likely.
Trading System Selection Bias: Some Conclusions
In general, it is important to realise that there are very few ‘edges’ available in the market that are exploitable for the average trader.
The avoidance of curve-fitting is a systems trader’s major concern because it is one of the most common and easiest errors to make. The more simulations that are run, the more likely it is that this mistake will occur.
Trading systems should be simple and robustness should be preferred over outlandish returns. So traders need to be cautious about curve fitting every step of the way and use statistics to gain more confidence in their results. Traders should be aware that selection bias/curve fitting can occur in out-of-sample just as in the in-sample.
Great article and great blog. Kind regards. Roman!
Thank you!